1. 소스코드와 명령어
1-1. 고급언어와 저급언어
- 고급언어 : 컴퓨터가 이해하는 언어가 아닌 사람이 이해하고 작성하기 쉽게 만들어진 언어
- 저급언어 : 컴퓨터가 직접 이해하고 실행할 수 있는 언어
- 기계어 : 0과 1의 명령어 비트로 이루어진 언어. 가독성을 위해 16진수로 표현하기도 함.
- 어셈블리어 : 0과 1로 이루어진 기계어를 읽기 편한 형태로 번역한 저급 언어.
1-2. 고급언어의 저급언어 변환 방법
- 컴파일 방식
- 컴파일 언어 : 컴파일러에 의해 소스코드 전체가 저급언어로 변환되어 실행되는 고급 언어. ex) C언어
- 컴파일 : 컴파일 언어로 작성된 소스 코드 전체가 저급 언어로 변환되는 과정.
- 컴파일러 : 컴파일을 수행해 주는 도구. 소스 코드 내에 오류가 하나라도 발견된다면 컴파일 실패.

- 인터프리트 방식
- 인터프리터 언어 : 인터프리터에 의해 소스 코드가 한 줄씩 실행되는 고급 언어. ex) python
- 인터프리터 : 소스 코드를 한 줄씩 저급언어로 변환하여 실행해 주는 도구.
- 소스 코드를 한 줄씩 실행하기 때문에 소스 코드 N번째 줄에 오류가 있다면 N-1번째 줄까지는 올바르게 수행.
- 컴파일 언어 vs 인터프리터 언어
※ 목적 파일 vs 실행 파일
- 목적 파일 : 목적 코드로 이루어진 파일
- 실행 파일 : 실행 파일로 이루어진 파일
- 차이점?
- 외부 기능들이 포함되어 있는 목적 코드는 실행될 수 없다!
- 실행 파일이 되기 위해선 외부 기능들을 연결해줄 linking 작업이 필요.
2. 명령어의 구조
2-1. 연산 코드와 오퍼랜드
- 명령어의 구조
- 연산 코드
- 명령어가 수행할 연산.
- '연산자'라고도 불림
- 기본적인 유형 4가지
- 데이터 전송
- MOVE, STORE, LOAD(FETCH), PUSH, POP
- 산술 / 논리 연산
- ADD, SUBTRACT, MULTIPLY, DIVIDE
- INCREMENT, DECREMENT
- AND, OR, NOT: AND, OR, NOT
- COMPARE
- 제어 흐름 변경
- JUMP, CONDITIONAL JUMP, HALT, CALL, RETURN
- 입출력 제어
- READ, WRITE, START IO, TEST IO
- 데이터 전송
- 오퍼랜드
- '연산에 사용할 데이터' 또는 '연산에 사용할 데이터가 저장된 위치'
- '피연산자'라고도 불림
- 숫자와 문자 등을 나타내는 데이터 또는 메모리나 레지스터 주소가 해당.
- 연산에 사용할 데이터를 직접 명시하기보다 많은 경우에 연산에 사용할 데이터가 저장된 위치, 즉 메모리 주소나 레지스터 이름이 담기기 때문에 주소 필드라고 불린다.
- 오퍼랜드가 하나도 없는 명령어를 0-주소 명령어, 하나인 경우 1-주소 명령어, 2개인 경우 2-주소 명령어, 3개인 경우 3-주소 명령어 ... 라고 한다.
- 연산 코드
2-2 주소 지정 방식
- 오퍼랜드에 데이터를 직접 명시하지 않고 메모리 주소나 레지스터 이름을 담는 이유?
- 명령어 길이의 한계 때문.(표현할 수 있는 길이)
- 유효 주소
- 연산 코드에 사용할 데이터가 저장된 위치.
- 연산의 대상이 되는 데이터가 저장된 위치를 유효 주소라고 한다.
- 위 그림의 경우 10번지가 유효 주소에 해당
2-3. 명령어 주소 지정 방식
- 연산에 사용할 데이터가 저장된 위치를 찾는 방법
- 유효 주소를 찾는 방법
- 대표적인 주소 지정 방식 5가지
- 즉시 주소 지정 방식 (연산에 사용할 데이터)
- 연산에 사용할 데이터를 오퍼랜드 필드에 직접 명시하는 방식
- 장점 : 연산에 사용할 데이터를 메모리나 레지스터로부터 찾는 과정이 없어 빠르다.
- 단점 : 표현할 수 있는 데이터의 크기가 작다.
- 직접 주소 지정 방식 (유효 주소)
- 오퍼랜드 필드에 유효 주소를 직접적으로 명시하는 방식
- 장점 : 오퍼랜드 필드에서 표현할 수 있는 데이터의 크기는 즉시 주소 지정 방식보다 크다.
- 단점 : 여전히 유효 주소를 표현할 수 있는 범위가 연산 코드의 비트 수만큼 줄어듦.
- 간접 주소 지정 방식 (유효 주소의 주소)
- 오퍼랜드 필드에 유효 주소의 주소를 명시
- 두 번의 메모리 접근이 필요하기 때문에 앞선 주소 지정 방식들에 비해 속도가 느림
- 레지스터 주소 지정 방식 (유효 주소(레지스터 이름))
- 연산에 사용할 데이터를 저장한 레지스터를 오퍼랜드 필드에 직접 명시하는 방법
- 장점 : CPU가 메모리에 접근하는 속도보다 레지스터에 접근하는 속도가 빠르기 때문에 직접 주소 지정 방식보다 빠르다.
- 단점 : 표현할 수 있는 레지스터 크기에 제한이 생길 수 있다.
- 레지스터 간접 주소 지정 방식 (유효 주소를 저장한 레지스터)
- 연산에 사용할 데이터를 메모리에 저장하고, 그 주소(유효 주소)를 저장한 레지스터를 오퍼랜드 필드에 명시하는 방법
- 장점 : 메모리에 접근하는 횟수가 한 번으로 간접 주소 지정 방식보다 빠르다.
- 즉시 주소 지정 방식 (연산에 사용할 데이터)
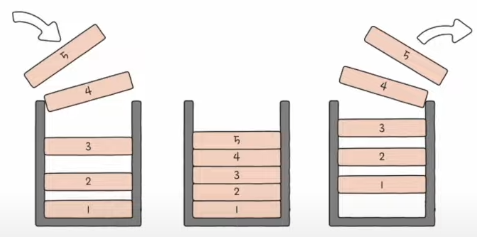
※ 스택과 큐
- 스택
- 한쪽 끝이 막혀 있는 저장 공간
- 나중에 저장한 데이터를 가장 먼저 빼내는 데이터 관리 방식. 후입선출(LIFO)
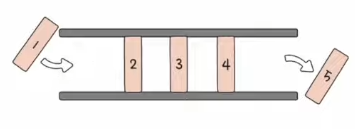
- 큐
- 양쪽이 뚫려 있는 저장 공간
- 가장 먼저 저장된 데이터부터 빼내는 데이터 관리 방식. 선입선출(FIFO)
* 출처 : 혼자공부하는컴퓨터구조+운영체제
'CS > 컴퓨터구조' 카테고리의 다른 글
| CPU의 작동 원리 (1) | 2022.09.20 |
|---|
